Published on Netflix Tech Blog
Samuel Fu, Prudhviraj Karumanchi, Sriram Rangarajan, Vidhya Arvind, Yun Wang, John Lu, Netflix Inc
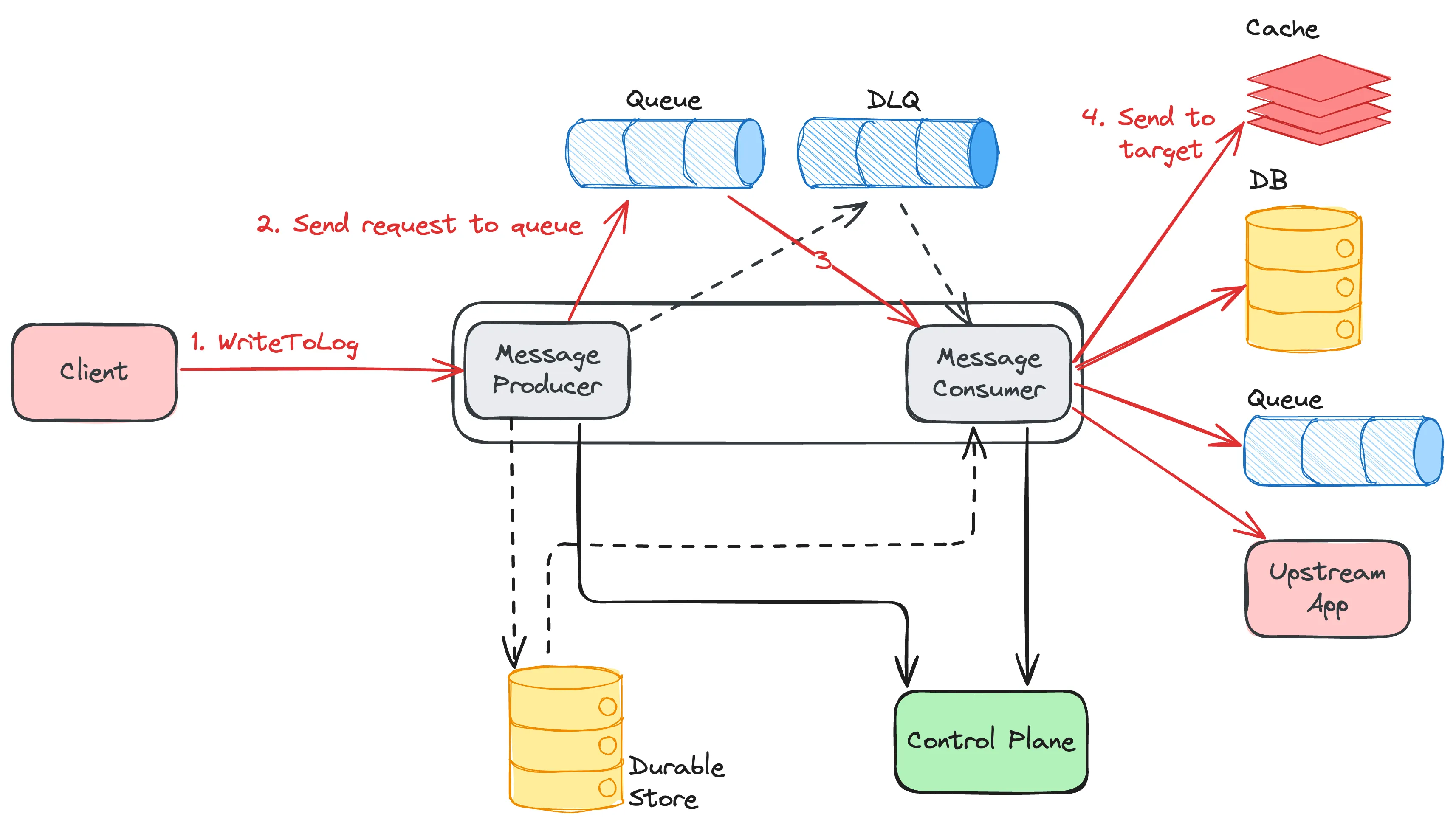
Netflix operates at a massive scale, serving hundreds of millions of users with diverse content and features. Behind the scenes, ensuring data consistency, reliability, and efficient operations across various services presents a continuous challenge. At the heart of many critical functions lies the concept of a Write-Ahead Log (WAL) abstraction. At Netflix scale, every challenge gets amplified. Some of the key challenges we encountered include:
All the above challenges either resulted in production incidents or outages, consumed significant engineering resources, or led to bespoke solutions and technical debt. During one particular incident, a developer issued an ALTER TABLE command that led to data corruption. Fortunately, the data was fronted by a cache, so the ability to extend cache TTL quickly together with the app writing the mutations to Kafka allowed us to recover. Absent the resilience features on the application, there would have been permanent data loss. As the data platform team, we needed to provide resilience and guarantees to protect not just this application, but all the critical applications we have at Netflix.
Regarding the retry mechanisms for real time data pipelines, Netflix operates at a massive scale where failures (network errors, downstream service outages, etc.) are inevitable. We needed a reliable and scalable way to retry failed messages, without sacrificing throughput.
With these problems in mind, we decided to build a system that would solve all the aforementioned issues and continue to serve the future needs of Netflix in the online data platform space. Our Write-Ahead Log (WAL) is a distributed system that captures data changes, provides strong durability guarantees, and reliably delivers these changes to downstream consumers. This blog post dives into how Netflix is building a generic WAL solution to address common data challenges, enhance developer efficiency, and power high-leverage capabilities like secondary indices, enable cross-region replication for non-replicated storage engines, and support widely used patterns like delayed queues.